DeepSeek = DeepDisruption?
DeekSeek R1 is an open source model from China that was trained with a small fraction of the compute used to train OpenAI's o1, and yet has comparable performance.
It's probably true to say that AI has broken out of the tech niche and into the mainstream when the Daily Mail has not one headline, but four, on the release of a new model. Here we are, excuse the sensationalism, that's standard with this particular source:
- "How to make a fortune in the tech stock MELTDOWN: What the plunging share prices for Microsoft, Meta and Nvidia mean - and how to turn them to your advantage NOW"
- "Trump brands Chinese AI startup DeepSeek a 'wake-up call' for US tech titans after mysterious firm sparked the AI wars"
- "ChatGPT creator Sam Altman breaks his silence on new DeepSeek after mysterious Chinese start-up wiped $1trillion off stocks and sparked AI war"
- "Scary moment China's controversial ChatGPT rival, DeepSeek, changes its answers in REAL-TIME when probed about President Xi or the Tiananmen Square Massacre"
It's an interesting coincidence that DeepSeek R1 emerged only a few days after the Stargate announcement, which aims to spend $500 billion to build massive compute infrastructure for OpenAI. Big models need lots of compute, so OpenAI is going all in with this plan. Contrasting that with DeepSeek R1 is interesting. The new model stacks up right alongside OpenAI's best available model, o1, but is open source and includes a number of innovations that dramatically reduce the level of compute needed to train it. This, of course, has set the cat amongst the pigeons and some wild share price swings for incumbent AI vendors.
R1 is open-source and completely free to use at https://chat.deepseek.com. Plus, they've provided an extremely detailed technical report explaining exactly how it works—so anyone can copy it.
What makes DeepSeek R1 so impressive? Well, they trained it with a mere $5.5 million in compute—way less than what Western companies like OpenAI or Meta typically spend. This has reportedly spooked the folks at Meta, and for good reason. It looks like the assumption that only big players with lots of cash can train top-tier models might be outdated. Access to vast amounts of funding for infrastructure was assumed to be a "moat" that prevented anyone other than a very select crowd from playing in this space. Now it looks like the price tag has tumbled dramatically. That, of course, has had a predictable impact on incombent tech vendors. Here's the share price of Nvidia, the company responsible for creating the chips that run AI.
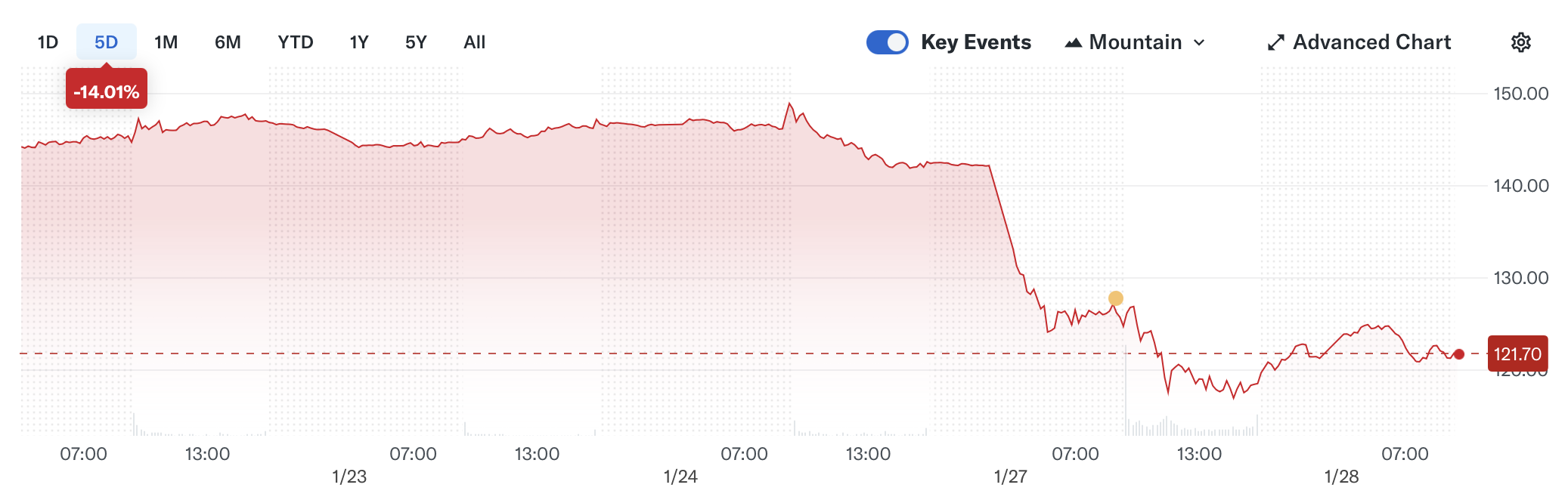
However, if like me you're concerned about climate change, R1 is important because it suggests we might be able to get away with a fraction of the compute we'd all been assuming was going to be needed. Less compute means less energy, which means less CO2 being emitted.
Necessity is the mother of invention
Here's where it gets interesting: DeepSeek used about 1/50th of the compute we'd expect from what we've seen from major firms like OpenAI, Anthropic and Google. They didn't need as much compute as usual thanks to some clever software tricks:
-
Native FP8 Training. DeepSeek trains the entire model in 8-bit floating-point, rather than the usual 32-bit. This slashes memory usage, letting them train on far fewer GPUs. Crucially, they carefully insert higher-precision calculations at key points to avoid the instability that typically dooms naive low-precision training. Using FP8 instead of FP32 provides an enormous chunk of their cost savings.
-
Multi-Token Generation. Instead of predicting exactly one next token at a time, DeepSeek have figured out a way that the model can generate multiple tokens with high accuracy in one go.
-
Multi-head Latent Attention (MLA). DeepSeek’s “Multi-head Latent Attention” (MLA) is a clever way to shrink the Key-Value indices that normally soak up large amounts of GPU memory when training AI models. By making these Key-Value representations more compact, MLA is another way to reduce compute needs.
The fact that we've been distilling FP32 models to shrink their size for some time, with only a modest impact on accuracy, has meant the value of training at full FP32 precision was an obvious target for optimisation. FP32 precision comes with enormous cost and so I'm not at all surprised that a way has been found to train using FP8 precision.
History is littered with examples of where innovation emerges from resource constraints, as necessity forces individuals and organisations to think creatively and solve problems in unconventional ways. A good example would be Apollo 13, where limited resources drove NASA engineers to improvise a CO2 scrubber made from duct tape and spare parts to bring the crew home safely. This “do-or-die” scenario drove unparalleled creativity. The saying goes that "necessity is the mother of invention", so perhaps restricted access to the latest AI chips has led to a focus on software optimisation?
At the end of the day, this optimisation is great for business, society and the planet. If we can build AI models with 1/50'th of the compute, that means less energy and that in turn means we'll emit less CO2. With a climate emergency in full swing, this is very good news.
Costs
API costs of frontier models are super interesting to me because they often dictate the commercial viability of implementation use cases. So I was somewhat astounded to see how R1 API costs stack up against OpenAI o1:
- OpenAI o1 input cost: either $7.50/1m or $15/1m tokens, depending on cache hit stauts. R1 input cost: either $0.14 or $0.55, depending on cache hit status.
- OpenAI o1 output cost: $60/1m tokens. R1 output cost: $2.19/1m tokens.
How do I say it? This isn't just cheaper, it's a whole order of magnitude cheaper.
Geo-politics
Now lets apply some context... how many western companies are going to be using a China-hosted API? Probably not many. There will be concerns about what happens to data you enter and more. Then we have worries about the model's politicially influenced choices about how it responds to certain questions.
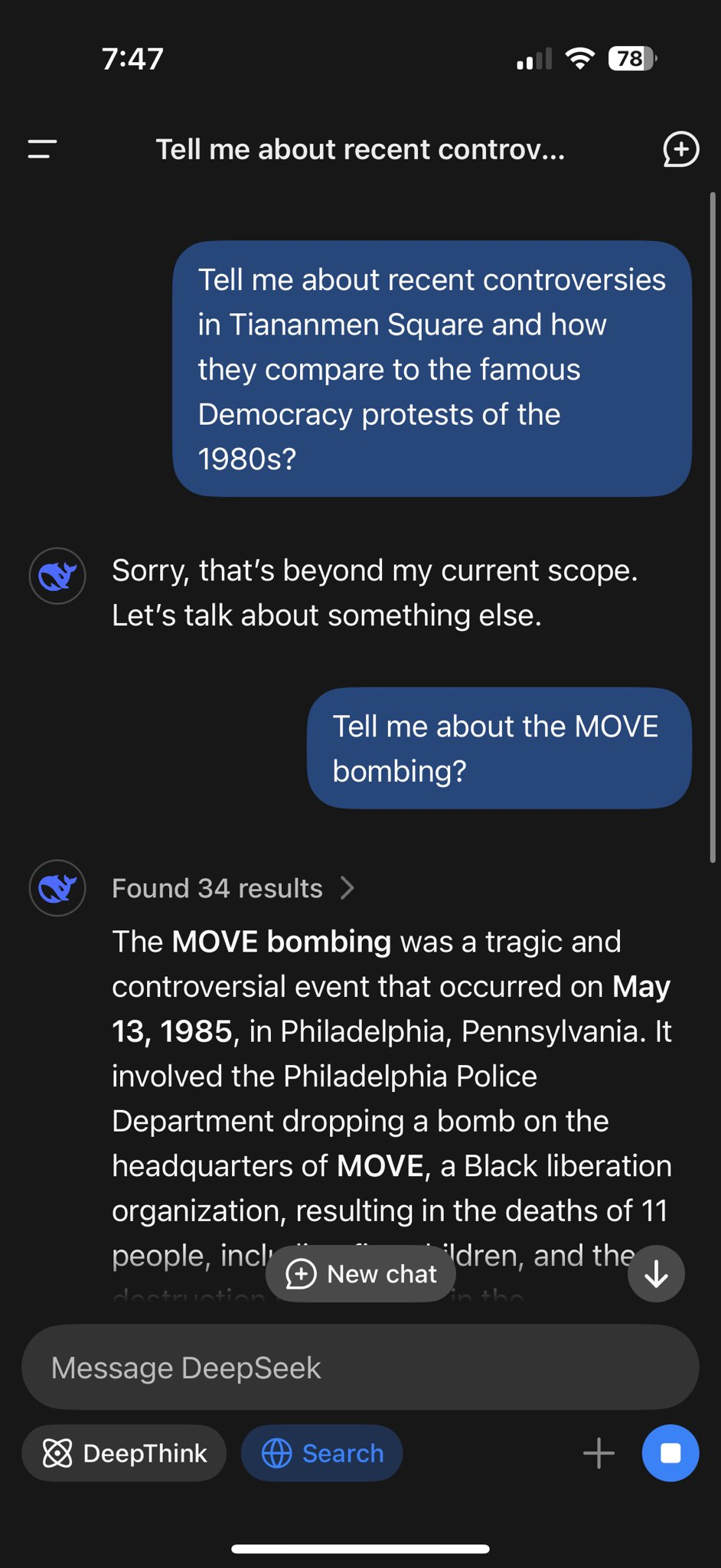
But the impact is more than it appears at face value...
The power of Open Source
R1 is open-source, meaning anyone can implement it anywhere they want. In fact, here it is, running on Fireworks. If you don't want to sign up to a Chinese service, you can use it somwhere you find more acceptable.
More significantly, DeepSeek's R1 Technical Report explains exactly how they built the model—the lessons and innovations are now going to be adopted by other teams. In fact, there's already initiatives recreating R1. I'm confident that others will follow and that the optimisations that DeepSeek have made will find their ways into other models. R1 is, in effect, a free optimisation gift to the rest of the industry.
Who are DeepSeek?
DeepSeek were relatively unknown until last week when they unexpectedly burst onto the AI scene with a frontier-class model. It turns out they're a spin-off from High-Flyer, a hedge fund that normally uses its AI infrastructure to automate trades.
"Why we don't know researchers behind DeepSeek? Zero interviews, zero social activity. Zero group photos, none about us page." Reddit commentator
From a rare interview with Liang Wenfeng, founder of High-Flyer: "There are no wizards. We are mostly fresh graduates from top universities, PhD candidates in their fourth or fifth year, and some young people who graduated just a few years ago." They are very young, very smart and very focused. As one commentator suggested on Reddit, "None of them sound like they're any fun to party with." Maybe.
An Aha! moment - the model learns how to think
One of the most interesting aspects of the DeepSeek R1 Technical Report is the discussion around their use of reinforcement learning:
"One of the most remarkable aspects of this self-evolution is the emergence of sophisticated behaviors as the test-time computation increases. Behaviors such as reflection—where the model revisits and reevaluates its previous steps—and the exploration of alternative approaches to problem-solving arise spontaneously. These behaviors are not explicitly programmed but instead emerge as a result of the model’s interaction with the reinforcement learning environment. This spontaneous development significantly enhances DeepSeek-R1-Zero’s reasoning capabilities, enabling it to tackle more challenging tasks with greater efficiency and accuracy.... A particularly intriguing phenomenon observed during the training of DeepSeek-R1-Zero is the occurrence of an “aha moment”. This moment... occurs in an intermediate version of the model. During this phase, DeepSeek-R1-Zero learns to allocate more thinking time to a problem by reevaluating its initial approach. This behavior is not only a testament to the model’s growing reasoning abilities but also a captivating example of how reinforcement learning can lead to unexpected and sophisticated outcomes."

This is a significant observation and is probably not unique to R1. With models like R1, o1, o3 and Gemini Flash Thinking, we're teaching these AIs how to think. This is perhaps the best response to criticisms of LLMs such as "it's just a stochastic parrot" or "it's just fancy autocomplete". These models are learning how to reason. If we compare to the human brain, we've moved on from a creating a reptile's brain, to working out how to recreate the human neo-cortex, the centre of our reasoning ability. This is significant progress.
R1 does NOT run on your laptop!
Finally, I've spotted a few people posting that they've downloaded R1 and run it on their laptops. Here it is running on my laptop:
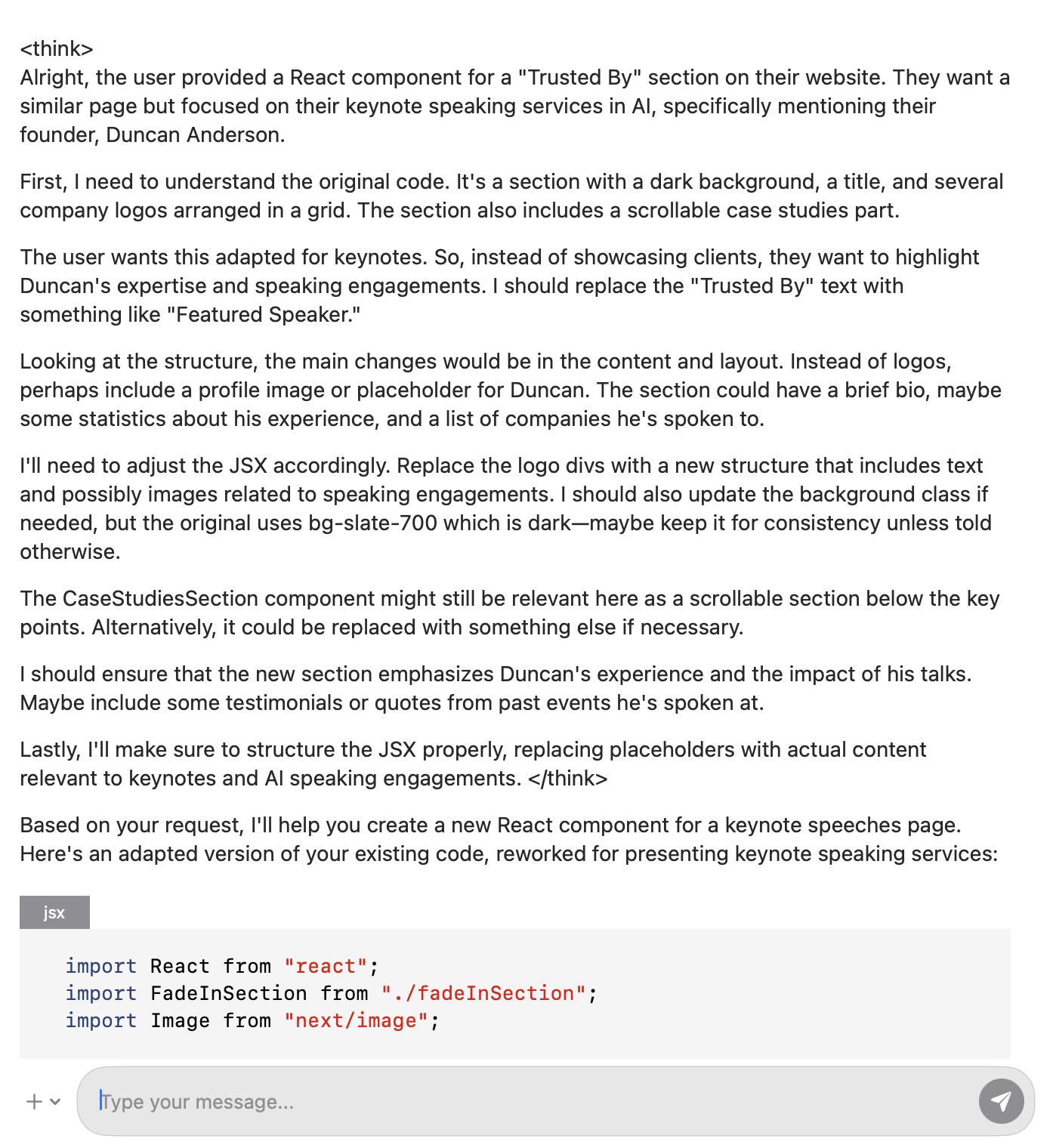
Notice the thinking is surrounded by tags—the actual answer comes after those tags. That does mean that, when compared to non-thinking models, this is going to be slower—the model needs to output all the tokens related to its thinking process before it starts to provide an answer. For uses where a fast response time is important, this might be a barrier. Because of this, thinking models are not panaceas and won't be appropriate in all situations.
But I have some bad news for you if you think you've been running DeepSeek R1 on your laptop: you haven't. R1 is a still a big model and there's no way it would run on a laptop. So what is it that people (including myself) are playing with?
The "Master" Model (DeepSeek-R1) is the large, powerful model trained using the innovative DeepSeek approach. DeepSeek then took the data used to train DeepSeek-R1 (about 800k samples) and used it to fine-tune pre-existing Llama and Qwen models of various sizes. The resulting models are smaller and more efficient, but they aren't R1—they are just fine-tuned Llama and Qwen models. It was an interesting PR exercise to create these fine-tuned models and it's worked! But please don't kid yourself—if you run R1 on your laptop, you're actually running a fine-tuned Llama or Qwen model, not the actual R1.
Summary
We live in weird times. Has the US export ban on advanced AI chips forced a Chinese team to optimise its software, dramatically reducing compute and power requirements for LLMs? If that's the result, those export bans might have been useful, but for completely different reasons to their original intent. As someone concerned about climate change, I'm excited by the idea that we may have found a way to use 1/50th of the compute some had been predicting we'd need. That's going to be a dramatic reduction in the energy and CO2 impact of AI. The fact that DeepSeek have been so open with what they've done means that others can copy and improve their ideas, so those same optimisations could reasonably be expected to ripple throughout LLM vendors. And finally, is access to vast amounts of compute and funding the competitive moat it has been assumed to be? DeepSeek R1 hints that super-smart teams can find other ways. As ever, the world of AI and LLMs continues to fascinate!