The wall that wasn’t
Benchmark results for the latest AI models suggest that any “scaling wall” has already been breached and we’re on the path to AGI.

In The Hitchhiker’s Guide to the Galaxy, the supercomputer Deep Thought spent 7.5 million years computing the answer to “The Ultimate Question of Life, the Universe, and Everything.”
Today, we’re deploying our own “Deep Thoughts” in the form of advanced AI “reasoning” models: OpenAI’s just announced o3 and o3-mini as advances over the still leading-edge o1 and o1-mini, Google’s Gemini Flash Thinking and Alibaba’s QWQ. These models might not take 7.5 million years to compute an answer, but like Deep Thought they can extend the amount of compute used at inferencing time and can sometimes take a minute or more to solve tricky problems. A case of reality aping science fiction?
The Scaling Wall That Wasn’t
In recent months there’s been talk that we’re hitting AI scaling walls with the transformer architecture–that piling on the model size for LLMs was resulting in diminishing returns. Evidence for this was the fact that we haven’t seen a dramatic breakthrough in frontier models for, oh, at least six months.
So what’s the actual evidence that AI scaling progress has stalled?
At the start of 2024, AI models were scoring 5% on the ARC-AGI benchmark.
In September, we were at 32%.
Now, with OpenAI’s new o3, and only 3 months later, we’re at 88%.
Just over a month ago, Epoch AI introduced FrontierMath, a benchmark of expert-crafted maths problems designed to evaluate advanced reasoning in AI systems. These are problems so hard that:
"Each problem demands hours of work from expert mathematicians. Even the most advanced AI systems today, including GPT-4 and Gemini, solve less than 2% of them." — EpochAI
But OpenAI’s o3 has just leapt ahead and scores 25%. We now have a AI model that’s not just good at maths, but so good at maths that it rivals human PhD-level capability.
I tested this with an undergrad friend who’s studying maths. She told me “AI is no good at maths”, so I asked her to give me a complex maths challenge that I then gave to OpenAI’s o1. It solved the challenge and my friend changed her opinion of AI!
The talk of AI scaling walls, like munch conjecture, originates from a germ of truth: We must inevitably reach a point where there’s diminishing returns to be had from just making AI models bigger. That seems obvious, but it also misses the point that there are many other innovations that can increase model performance.
The advances we’ve seen in 2024 have been achieved primarily through a single architectural innovation, the use of Chain of Thought techniques. But there are other innovations floating around–MoE, Mamba and many more. The LLM world is full of ideas as to how to scale beyond just making things bigger.
What Is “Chain of Thought” and Why Does It Matter?
At the heart of models like OpenAI’s o1 and o3, Google’s Gemini-Flash-Thinking and Alibaba’s QWQ, is a concept called Chain of Thought (CoT). The original paper on Chain of Thought is here for those who want to delve into the details.
As a side note, it’s notable that the original paper that introduced the Transformer architecture (Attention is all you need), the paper detailing the Mixture of Experts architecture (Outrageously Large Neural Networks: The Sparsely-Gated Mixture-Of-Experts Layer) used by a number of top LLMs and this one on Chain of Thought (Chain-of-Thought Prompting Elicits Reasoning in Large Language Models) were all published by the Google Brain team. I don’t think it’s unfair to state that without Google Brain and its open publishing of research, LLMs would not be where they are today. This is but one example of “open science”, but a good one because it demonstrates how open publishing allows ideas to spread and advance an entire field in ways that would be impossible if the knowledge were kept within a single institution.
Getting back to CoT, it’s a technique where a large language model is prompted in ways that encourage it to “walk through” its reasoning steps — much like showing its work on a maths problem. CoT prompting gives the model examples of how to reason about a problem, examples which it can then use to break a user’s problem down into steps. Models like o1 and o3 incorporate CoT techniques within the model itself and incorporate a wide variety of reasoning styles in order to give the model options.
As a result, these reasoning models don’t jump directly from a question to an answer, but instead outline intermediate steps, or partial conclusions, before going on to deliver a final result.
CoT results in:
- Breaking Down Complexity: By articulating smaller steps, the model can handle more complicated or multi-stage tasks. Think of it like solving a multi-variable equation one variable at a time.
- Improved Accuracy: Having these intermediate steps makes it easier for the model to check and refine its logic, leading to fewer mistakes on difficult problems.
- Greater Interpretability: While these steps aren’t necessarily guaranteed to align with how humans reason, they can still give developers and end-users a useful “peek under the hood” to see whether an answer looks plausible or not based on how the model arrived at its conclusion.
We don’t know the exact details of how CoT is used in these models, because that is kept commercially confidential. What we do know is that all these reasoning models are using CoT and that it has a significant impact on model performance.
CoT works very simply by prompting a model with examples of problems and the reasoning steps used to solve them, then asking the model to use that as a guide to solve a new problem.
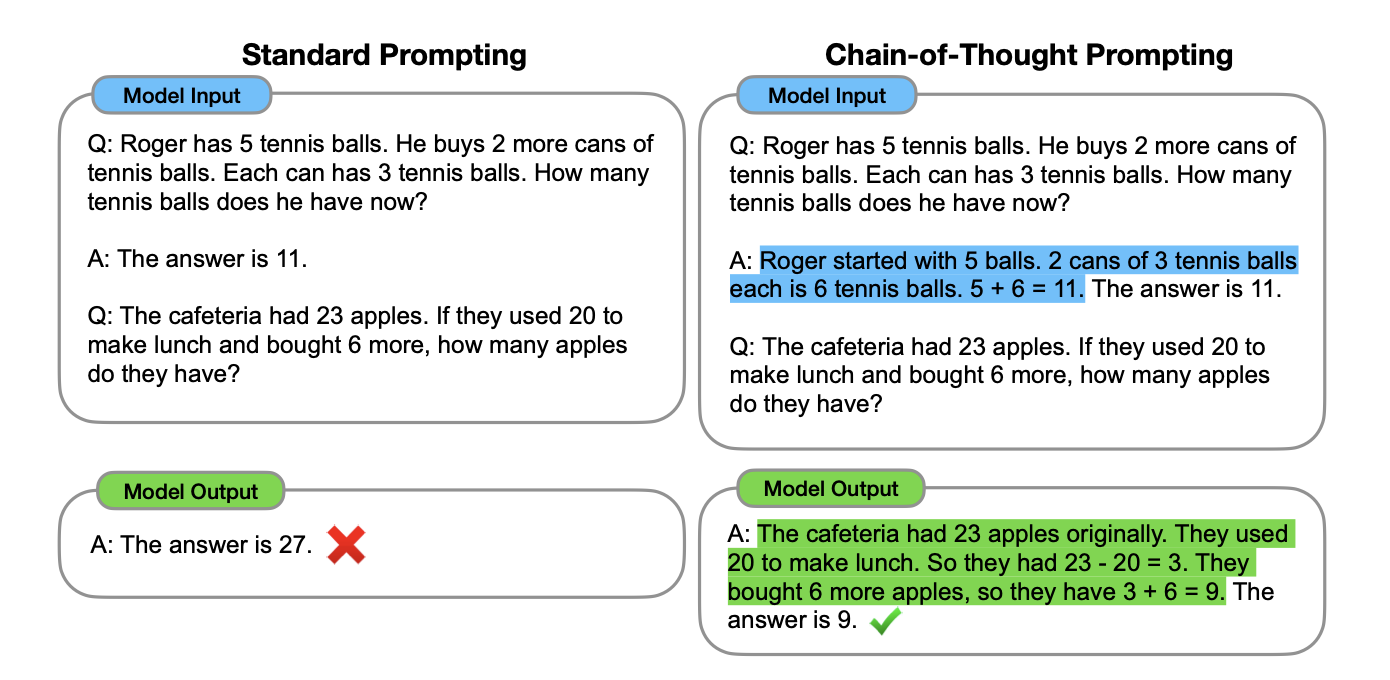
A model using Chain of Thought can be instructed internally with a variety of different reasoning techniques–think one way to solve a particular branch of maths problems and a different way to solve coding challenges. If this library of reasoning techniques is broad enough, the model has an array of possible approaches to problem solving that it can choose from. It can even try multiple routes and compare the results before responding. We know that at least the OpenAI models do this because you can specify how much compute you want them to use to arrive at an answer. Essentially you’re specifying how much CoT “work” should be performed and how many different reasoning paths the model should explore. It’s no surprise that if the model is allowed to explore more paths, it usually arrives at a better conclusion.
From Rigid Rules to Flexible Thinking
In previous eras of AI the focus was on trying to break a domain down into a set of rules that can be encoded, but in this era we’re instead focusing on teaching the machine how to think about problem solving. This is clearly a big upgrade, as the machine is able to apply its knowledge of problem solving to domains and problems it’s not previously seen.
However, rules-based systems suffer from challenges that their proponents rarely acknowledge: the messy reality of most domains is that the experts don’t know what those rules are. Or, the rules are so labyrinthine in their complexity that the humans who curate them often make mistakes in their definitions. As a result, rules-based systems are not as accurate as some might have us believe.
"[A]n expert’s knowledge is often ill specified or incomplete because the expert himself doesn’t always know exactly what it is he knows about his domain.” - Feigenbaum and McCorduck, The Fifth Generation: Artificial Intelligence and Japan’s computer challenge to the world.
The ability to tap into different approaches to problem solving and try different approaches, rather than follow a rigid set of rules, means the latest AI models end up exhibiting remarkable levels of “intelligence”.
However, for simple “who’s the US president” type questions, you’re not going to notice a difference. To experience what so-called reasoning models can do, you need to ask complex questions that require a deeper level of reasoning than basic information retrieval. This is why some who have tested these models have come away underwhelmed. It’s a bit like having a cocktail party chat with a PhD student–a superficial discussion about global politics is unlikely to help you discern the students grasp of the maths associated with black-holes.
Scaling inference compute, rather than training compute
Most of us assumed that “scaling” an LLM meant making it bigger with more parameters, training on more data, training for longer, etc. i.e. we were trapped into an assumption that “scaling” meant scaling-up the resources needed to train a model.
However, it turns out that you can also scale the compute used during inferencing, which is exactly what these reasoning models do. This approach is detailed in another research paper from the Google Brain team, “Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters”. In other words, models like OpenAI’s o3 are clever not because they’ve been made bigger, but instead because a model of a similar size has been empowered to “do more stuff” when it’s posed a question. This isn’t the kind of scaling the “scaling wall” aficionados were thinking of, but it is scaling.
Interestingly, Google’s research demonstrates that there are trade-offs to be made as to whether you scale training or inference compute and those trade-offs affect different capabilities of the a model in different ways. In other words, there is no single answer–it’s complicated! As LLMs further evolve, I fully expect a wider variety of techniques to be used, with different teams potentially preferring different mixtures. In other words, there is no single answer as to how we build more intelligent machines, just as mother nature didn’t have a single answer for how to build intelligent life.
When considering how AI will likely evolve over the next decade, we need to move away from the notion of a single, straightforward trajectory. Instead, its development is more likely to resemble a maze of meandering paths rather than a single, clear, well-defined road.
Where “Reasoning Models” are having an impact
CoT gives AI systems the appearance of greater intelligence, making tasks like advanced scientific Q&A or tricky logic puzzles far more tractable. Benchmarks confirm it: o3 scores significantly higher than prior models on multiple metrics, showing near-human or even superhuman capabilities on some specific tests. OpenAI specifically calls out scientific Q&A, maths and logic puzzles as areas that o3 excels at.
However, most areas of business do not resemble any of those three domains. Does this mean that such models are mere curiosities? I don’t think it does. One domain where the tricky logic puzzle ability has clear applicability is software engineering. From personal experience using o1 for this task, I can attest that breaking down a complex coding request into step-by-step tasks allows the AI to produce more accurate solutions and solve complex problems that other models cannot.
Every week since it’s release, I’ve watched o1 complete in a few minutes tasks that would otherwise have taken me an entire day. I’m an avid user of o1 and it brings significant value–dramatically more than the $20/month fee I pay. That is presumably why there’s now a “pro” subscription tier for $200/month. That’s quite a hike in price, but brings with it a “pro mode” where o1 can “think” for longer and solve more complex problems. Models like o1 mean the capabilities of AI are now at the level where the entire profession of software engineering is being transformed. New AI-native tools are emerging (Cursor, V0, Bolt, Windsurf, Lovable, etc.) and workflows and skills are changing significantly. The productivity benefits for those that embrace this change are nothing short of profound.
Not everyone gets it yet, and I’ve encountered my fair share of cynics. However, my personal experience has convinced me that they’re wrong. We’re on the cusp of radical change, and the field of Software Engineering is transforming before our eyes. In the future, we’ll view today’s programmers much like we now view those who coded in machine language, crafting algorithms that meticulously optimised behavior to conserve single bytes of storage.
If we can see this level of impact on Software Engineering, I see no reason to not blieve that other disciplines will follow. Software Engineering is just in the vanguard.
A word of caution
Tricky scientific Q&A and logic puzzles don’t look much like the business use cases I typically experience outside of coding. Instead, predictability and a stronger adherence to prompt instructions are what more mundane uses require.
The tendency of LLMs to sometimes ignore parts of a complex prompt is a significant issue in many business situations. The possibility that reasoning models might improve this, is enticing. But it’s early days and initial CoT-based models have had latency issues and high costs that made them too small to be drop-in replacements for simpler models.
OpenAI’s o3-mini and Google’s Gemini Flash Thinking stand out for being reasoning models that also have much improved latency. However, with o3-mini not yet released and Gemini Flash Thinking only available as an experimental model and with no confirmed final pricing, it’s too early to tell. If I was was a betting man, I’d say that by the end of 2025 most models will incorporate reasoning abilities.
But Is This AGI?
A definition of AGI from the ARC Prize states:
"AGI is a system that can efficiently acquire new skills and solve open-ended problems."
Under that definition, we’re not there yet. The ability to “efficiently acquire new skills” implies that the AI can learn on its own — without humans manually labeling or prompting. With true AGI, you wouldn’t need to build specialised systems for customer service or medical diagnosis needs; the AI would magically adapt itself to your domain by itself. That’s exciting (and perhaps a bit scary), but it isn’t anywhere close to what we have today.
Impressive but Not Intelligent (in the cat sense)
Case in point: o3’s milestone on GPQA Diamond, a benchmark of PhD-level science questions. o3 hits 87.7% accuracy, surpassing actual PhD experts (65%) and completely outclassing non-expert validators (34%), even when those validators had 30+ minutes and full internet access. Yet, o3 still can’t learn from new experiences in the real world or apply its reasoning across unrelated tasks on its own.
As Yann LeCun points out, not even the best large language models can yet compete with a cat’s abilities.
“A cat can remember, can understand the physical world, can plan complex actions, can do some level of reasoning—actually much better than the biggest LLMs. That tells you we are missing something conceptually big to get machines to be as intelligent as animals and humans.”
Cats can interact with a complex physical environment, learn in real-time and adapt their behaviour in ways that AI simply can’t replicate yet. Nobody needs to prompt a cat, it figures stuff out for iteself.
However, whilst models like o3 aren’t competing with cats, they are doing things that are arguably more useful. A cat can’t answer phd-level science questions or even solve customer service issues, but some clever humans could build a system with o3 that can. Perhaps we don’t need AGI? Catbert is, after all, fictional. AI models on the pathway to AGI might be just as useful as actual AGI in business contexts that often value predictability above an ability to “figure stuff out”.
Intelligence Too Cheap to Measure?
A striking aspect of OpenAI’s o3 is its cost. o1 is already expensive to run, and o3 is even more resource-intensive. OpenAI showed a graph hinting it can cost over $1,000 per task in some scenarios.
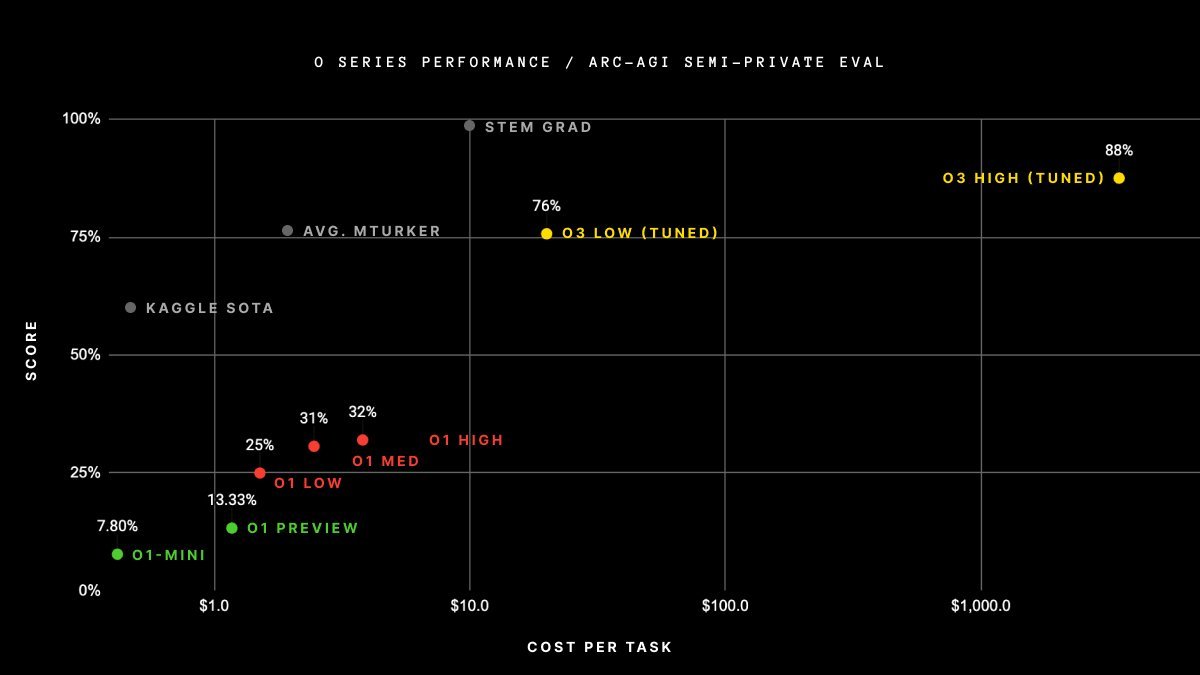
Enter o3-mini: early demos show that o3-mini outperforms o1 at a fraction of the cost and with latencies comparable to GPT-4o.
https://x.com/sama/status/1870266813248053426?s=61
Cost is important because it’s often what drives whether a use case is commercially viable or not. The key takeaway? Each new model generation lifts performance whilst reducing cost, and o3-mini exemplifies that trend.
Conclusion: The Road Matters More Than the Destination
We’re going to have the “Is this AGI, yet?” debate for years to come, as models become ever more impressive. That OpenAI’s o3 challenges human performance on some very complex uses is already prompting some to have the debate–it’s already started. The “It’s AGI!” voices are only going to get stronger each year, but watch out for when the arguments stop!
However, the technologies we develop en-route to AGI will be enormously impactful, not least because the truth is that most businesses do not require anything close to actual AGI. Models that “figure stuff out” for themselves are intriguing, but models that just reliably adhere to human instructions are going to bring about a huge amount of change.
That we’re seeing continual busting of benchmarks tells us we can ignore talk of “scaling walls”. Progress towards attaining any complex goal is rarely linear, so bumps along the way are to be expected. But evidence of a bump is not evidence that progress has stalled.
The combined brainpower and investment dollars going into AI research today means there are few walls that cannot be climbed or worked around. My money is on big advances over the next decade, even if those advances are “lumpy” in their arrival.